Introducing NebulaXChange
In this blog entry from 2007 I documented a new offering called NebulaXChange. As NebulaXLite creates rich spreadsheets from BASIC, NebulaXChange is intended to work on the opposite side, with Excel reaching into MV. After well over a year and a great deal of heartache NebulaXChange lives!
This is not even an Alpha offering yet, but I assure you it’s very functional and I’m eager to get it ready for some of our clients and colleagues to try.
The current development release supports the following formulas executed from Excel cells:
=NxRead("server","file,id,atb,val,sv","options")
=NxSave( "server","file,id,atb,val,sv",DataToSave,"options")
=NXExecute( "server","sub",Data,"options")
Operations will be available only to authorized users and admins will control access to specific resources.
Expand the two images below to get an idea of how it’s working so far. The first image shows three formulas retrieving data from consecutive values in a multi-valued attribute. Each value represents a month and the various graphs (a bit over the top really) change dynamically with the data coming from the server.
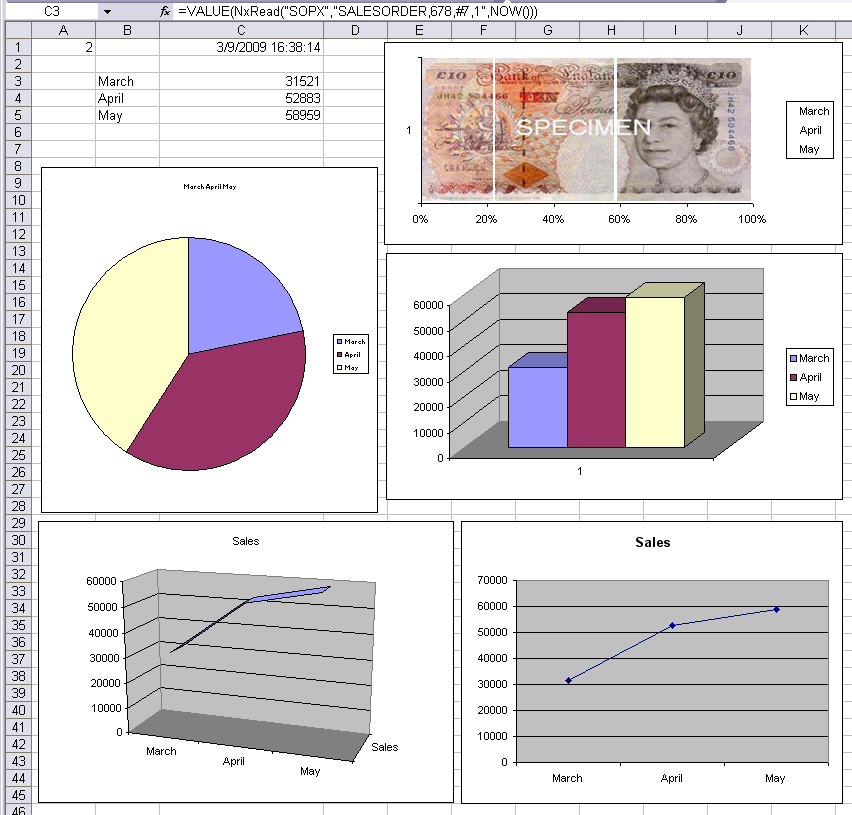
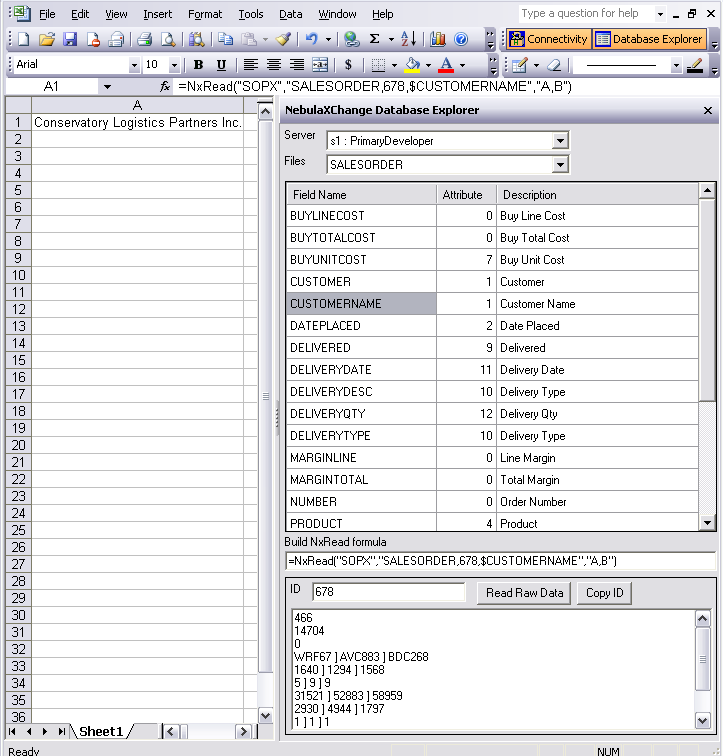
The NxRead formula can read from dict definitions (depending on connectivity) as well as directly from attribute numbers. This helps to return data that is calculated or translated on the server.
The NxExecute formula is an alternative to direct file access, allowing for calculated data and logging of requests.
The "options" parameter in formulas allows you to control when each cells get recalculated – eliminating unnecessary or undesirable round-trips to servers. When set to a quick refresh, numbers and charts update repeatedly from the servers. With the first image, for example, the data on the server was changing rapidly and Excel was polling every 2 seconds. The result is that all of the charts in that image were refreshing in real-time.
Various connectivity options to the DBMS will be supported, including mv.NET, UO.NET, D3 Class Library, QMClient, AccuTerm (embedded communications component), and web services. Not only does this mean that you can use NebulaXChange to connect to your DBMS with pretty much any connectivity option you already use, but users over the internet can now get data via web services without having to load communications components designed for LAN connectivity.
Supported servers will include all MV DBMS platforms, but this product will soon expand outside of the traditional MV market, providing data access to Caché, Amazon SimpleDB (yes, cloud data), and other environments. One of the implications of this is that you will be able to read from one environment and post updates out to another, allowing Excel worksheets to be created as a UI for inter-system data exchanges between MV, relational databases, web services, cloud resources, devices, and others.
Server Configuration and a Database Explorer are available from the Excel>Tools menu. These allow you to name a server which will be used in formulas, and change where that server ID points for any given user without needing to change existing documents.
The Database Explorer is also available as a task pane that sits next to a spreadsheet, so that you can browse defined servers, files, and dict definitions, read items to see their structure, and build formulas which simply need to be copied into the worksheet.
There are many other features implemented, planned, and contemplated. If you or your end-users have any interest in using NebulaXChange, please post inquiries in our new forum category for the product, or email Sales.
You will definitely be seeing more about NebulaXChange here, as well as some insight into the tools used to create it.
UPDATE: See this blog, I’m still moving forward with this…
1 thought on “Introducing NebulaXChange”
Leave a Reply
You must be logged in to post a comment.
Hi, If you are looking at SimpleDB take a quick look at CouchDB, an Apache project. It is described as a ‘document’ database. It appears to me to be what the Pick MV world might have evolved into. If it had not been sidetracked by the ‘Big R’ relational world (building SQL, ODBC, etc compatibility). I like the very simple interfaces, the use of JSON, RESTful access, etc.